Бинарный поиск
Дима загадал Паше некое число от $1$ до $100$, и задача Паши – отгадать это число как можно быстрее. Паша говорит Диме число, а Дима говорит, больше ли, меньше или равно названное число загаданному. Паша может пробовать все числа от $1$ до $100$ – $1$, $2$, $3$, $4$… но это долго. Немного подумав, Паша нашел оптимальный способ.
Он спросил число $50$. Дима ответил: “Мало”. Паша обрадовался, пусть он не угадал с первой попытки, но он уже забраковал половину всех чисел. Дальше он назвал число $75$ – “Много”. Паша отсек еще четверть чисел. Теперь он назовет число $63$ – “Много”. Следующая догадка – $57$ – “Угадал”.
Паша воспользовался алгоритмом бинарного поиска. Скорее всего, вы догадались, как он работает:
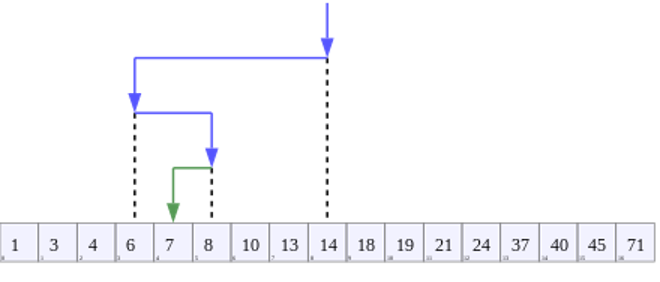
Мы проводим поиск элемента в отсортированном ряду чисел, при этом мы знаем его правую границу $R = 1$ и левую границу $L = 100$ (если представить, что ряд записан в строку от меньшего элемента к большему).
Мы сравниваем нашу догадку с центральным значением $M$ между правой и левой границей, $M = \frac{R + L}{2}$. Если оно больше искомого, мы присваиваем правой границе его индекс (в нашем случае, индекс значения в ряду от $1$ до $100$ совпадает самим значением), если меньше – левой границе. Так мы делаем до тех пор, пока центральное значение не будет равно искомому, то есть пока наши догадки не верны.
Стоит отметить, что на протяжении всего алгоритма поддерживается инвариант (неизменное условие) – нам всегда интересен только отрезок от левой до правой границы, и мы рассматриваем его пока индекс правой границы строго больше индекса левой на $1$.
int L = 1, R = 100;
while (R - L > 1) {
int M = (R + L) / 2
if (answer_for(M) == "много") {
R = M;
} else if (answer_for(M) == "мало") {
L = M;
} else if (anwer_for(M) == "угадал") {
break;
}
}
Этот алгоритм работает за $O(\log N)$ операций, в то время как линейный поиск (перебор всех элементов массива) работает за $O(N)$ в худшем случае (если искомый элемент окажется последним).
Теперь рассмотрим частую задачу о поиске данного числа $X$ в данном массиве $A$. Требуется найти индекс числа $X$ в массиве $A$ или сказать, что $X$ нет в массиве $A$. Стоит отметить, что массив должен быть отсортирован по условию или в самой программе, иначе алгоритм не сработает.
Для решения задачи добавим в массив фиктивные элементы с индексами $-1$ и $N$. Так как $A_{-1} \leq A_0 \leq A_i \leq A_{N-1} \leq A_N$ и $A_i \neq A_{-1}$ и $A_i \neq A_N$ поставим границы поиска $R = -1$ и $L = N$. Далее стоит выбрать один двух инвариантов.
Lower Bound
Данный инвариант заключается в выполнении следующих условий:
- $A_L < X$
- $A_R \geq X$
void lower_bound (vector<int> A, int X){
int L = -1, R = a.size();
while (R - L > 1) {
int M = (R + L) / 2;
if (A[M] < X) {
L = M;
} else {
R = M;
}
}
}
После того, как алгоритм бинарного поиска с таким инвариантом завершит работу, правая граница $R$ будет указыть на элемент $X$. Если $A_R \neq X$ или $R = N$, то $X$ нет в массиве $A$. В остальных случаях, когда $A_R = X$, индекс R будет указывать на первое вхождение элемента $X$ в $A$.
Upper Bound
Данный инвариант заключается в выполнении следующих условий:
- $A_L \leq X$
- $A_L > X$
void lower_bound (vector<int> A, int X){
int L = -1, R = a.size();
while (R - L > 1) {
int M = (R + L) / 2;
if (A[M] <= X) {
L = M;
} else {
R = M;
}
}
}
После того, как алгоритм бинарного поиска с таким инвариантом завершит работу, левая граница $L$ будет указыть на элемент $X$. Если $A_L \neq X$ или $L = -1$, то $X$ нет в массиве $A$. В остальных случаях, когда $A_L = X$, индекс $L$ будет указывать на последнее вхождение элемента $X$ в $A$.